ハイパースペクトラルセンサーデータの可視化¶
ハイパースペクトラルセンサーデータを用いて、Pythonでの基本的なデータ処理について学びます。
センサーデータのCSVから、以下のようなグラフと各測定でのNDVIの値を算出します。

上記のリンクからこの演習で利用するCSVデータをダウンロードの上、JupyterNotebookもしくはGoogle Colaboratoryの左側に表示されているファイルマネージャにてdataフォルダを作成し、その中に保存してください。
CSVファイルの読み込み¶
Pandasでは表形式のデータをDataFrameと呼ばれる形で保持し、必要な処理を行っていきます。
まずはPandasを用いてデータを読み込んでみましょう。
[1]:
import pandas as pd # pandasをpdという別名で呼び出す
# csvファイルを読み込み、dfという変数に代入する
df = pd.read_csv('data/spec.csv')
df # dfの中身を表示
[1]:
| DATE | 12/17/2019 | 12/17/2019.1 | 12/17/2019.2 | 12/17/2019.3 | |
|---|---|---|---|---|---|
| 0 | TIME | 13:08:32 | 13:07:44 | 13:06:19 | 13:04:52 |
| 1 | Model Number | MS-730 | MS-730 | MS-730 | MS-730 |
| 2 | Serial Number | 21151 | 21151 | 21151 | 21151 |
| 3 | Calibration Value | Available | Available | Available | Available |
| 4 | Measurement mode | Single | Single | Single | Single |
| ... | ... | ... | ... | ... | ... |
| 5043 | 1112.93 | 0 | 0 | 0 | 0 |
| 5044 | 1113.24 | 0 | 0 | 0 | 0 |
| 5045 | 1113.55 | 0 | 0 | 0 | 0 |
| 5046 | 1113.86 | 0 | 0 | 0 | 0 |
| 5047 | 1114.17 | 0 | 0 | 0 | 0 |
5048 rows × 5 columns
各行の意味はコメントに記載のとおりです。 Pandasライブラリには、今回利用したCSVファイルを読み込むためのread_csv()メソッド(関数)の他にも、エクセルファイルを読み込むためのread_excel()、クリップボードからデータを読み込むread_clipboard()などのメソッドが用意されています。詳しくはPandas API referenceで確認してください。
データは、dfにDataFrameというクラスで代入されています。
[2]:
# オブジェクトタイプの確認
type(df)
[2]:
pandas.core.frame.DataFrame
また、表示されるテーブルの最後に、5048 rows × 5 columnsと表示があり、CSVデータは5,048行、5列のデータであることがわかります。
このCSVデータは、列ごとに各観測が保存され、46行目までにメタデータ、47行目以降が各観測の波長ごとの放射照度(分光放射照度)の値が保存されています。また、2,548行目から別の測定が保存されています。
今回はメタデータ部分を飛ばして、かつ2,547行目までの放射照度の値のみを読み込んだデータフレームを作成します。
[3]:
spec = pd.read_csv('data/spec.csv', nrows=2500, skiprows=47)
spec
[3]:
| Wavelength[nm] | Spectral Irradiance[W/m^2/nm] | Spectral Irradiance[W/m^2/nm].1 | Spectral Irradiance[W/m^2/nm].2 | Spectral Irradiance[W/m^2/nm].3 | |
|---|---|---|---|---|---|
| 0 | 294.00 | 0 | 0 | 0.0 | 0.0 |
| 1 | 294.34 | 0 | 0 | 0.0 | 0.0 |
| 2 | 294.68 | 0 | 0 | 0.0 | 0.0 |
| 3 | 295.02 | nodata | nodata | 0.0 | 0.0 |
| 4 | 295.37 | 0 | 0 | NaN | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 2495 | 1112.93 | 0 | 0 | 0.0 | 0.0 |
| 2496 | 1113.24 | 0 | 0 | 0.0 | 0.0 |
| 2497 | 1113.55 | 0 | 0 | 0.0 | 0.0 |
| 2498 | 1113.86 | 0 | 0 | 0.0 | 0.0 |
| 2499 | 1114.17 | 0 | 0 | 0.0 | 0.0 |
2500 rows × 5 columns
skiprows=nオプションを与えることで、ファイルのはじめのn行を飛ばして読み込むことができました。その他のオプションは公式ドキュメントを参照してください。
データのクリーニング¶
読み込んだデータをプロットする前に、データのクリーニングとして以下を実施します。 - カラム名の変更 - 欠損値の設定
カラム名の変更¶
まずはカラムの名前が長すぎて扱いづらいので変更します。
データフレームはのカラム名は、作成したデータフレームの名前の後に.columnsを付けることで取得することができます。
[4]:
spec.columns
[4]:
Index(['Wavelength[nm]', 'Spectral Irradiance[W/m^2/nm]',
'Spectral Irradiance[W/m^2/nm].1', 'Spectral Irradiance[W/m^2/nm].2',
'Spectral Irradiance[W/m^2/nm].3'],
dtype='object')
.columnsに新しいカラム名を代入するとカラム名を変更することができます。
[5]:
spec.columns = ['WL','obs1','obs2','obs3','obs4']
spec
[5]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| 0 | 294.00 | 0 | 0 | 0.0 | 0.0 |
| 1 | 294.34 | 0 | 0 | 0.0 | 0.0 |
| 2 | 294.68 | 0 | 0 | 0.0 | 0.0 |
| 3 | 295.02 | nodata | nodata | 0.0 | 0.0 |
| 4 | 295.37 | 0 | 0 | NaN | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 2495 | 1112.93 | 0 | 0 | 0.0 | 0.0 |
| 2496 | 1113.24 | 0 | 0 | 0.0 | 0.0 |
| 2497 | 1113.55 | 0 | 0 | 0.0 | 0.0 |
| 2498 | 1113.86 | 0 | 0 | 0.0 | 0.0 |
| 2499 | 1114.17 | 0 | 0 | 0.0 | 0.0 |
2500 rows × 5 columns
データ型の変更¶
次に、データ型の変更です。
データフレームに格納されるデータは、同じ列の値がすべて同じ型のであることが必要です。今回は数値としてデータを扱いたいため、すべての列を浮動小数点のデータとして読み込みます。 まず、以下のコードで各列がどのような型で読み込まれているかを確認します。
[6]:
spec.dtypes
[6]:
WL float64
obs1 object
obs2 object
obs3 float64
obs4 float64
dtype: object
read_csv()関数は、各列に最適なデータ型を認識して読み込みます。読み込むデータに“NA”という文字列や値が無いセルは欠損値と認識し、浮動小数点のNaNという値に変換されます。 WaveLength、obs3、obs4の列はすべて数値(float64)として読み込むことができました。
obs1、obs2の列は、CSVファイルには数値の代わりにnodataの文字列が保存されている箇所があり、すべての値を数値に変換することができませんでした。 そのため、データフレームの各列はobjectの型で保持されています。
以下で、この数値に変換できなかった値を強制的にNaNへ変換し、すべての列を浮動小数点の型とすることができます。
[7]:
spec = spec.apply(pd.to_numeric, errors='coerce')
print(spec.dtypes)
spec
WL float64
obs1 float64
obs2 float64
obs3 float64
obs4 float64
dtype: object
[7]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| 0 | 294.00 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 294.34 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 294.68 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 295.02 | NaN | NaN | 0.0 | 0.0 |
| 4 | 295.37 | 0.0 | 0.0 | NaN | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 2495 | 1112.93 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2496 | 1113.24 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2497 | 1113.55 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2498 | 1113.86 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2499 | 1114.17 | 0.0 | 0.0 | 0.0 | 0.0 |
2500 rows × 5 columns
すべてのカラムが浮動小数点に変換されました。 先程nodataと表示されていた箇所も、NaNと表示されています。
基本統計量の確認¶
データフレームに保存されているデータの概要は、describe()メソッドで確認することができます。
[8]:
spec.describe()
[8]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| count | 2500.000000 | 2498.000000 | 2499.000000 | 2498.000000 | 2499.000000 |
| mean | 710.684948 | 0.000609 | 0.000877 | 0.000186 | 0.000648 |
| std | 237.214209 | 0.000588 | 0.000587 | 0.000285 | 0.000494 |
| min | 294.000000 | -0.000030 | -0.000551 | -0.001032 | -0.001259 |
| 25% | 505.997500 | 0.000285 | 0.000437 | 0.000000 | 0.000161 |
| 50% | 713.985000 | 0.000522 | 0.000895 | 0.000065 | 0.000732 |
| 75% | 917.030000 | 0.000761 | 0.001304 | 0.000327 | 0.001090 |
| max | 1114.170000 | 0.004639 | 0.003810 | 0.001553 | 0.001641 |
DataFrameクラスが持つcount()やmean()、std()などのメソッドを用いると、上記の基本統計量を個別に算出することができます。
[9]:
print(spec.mean())
print(spec.std())
WL 710.684948
obs1 0.000609
obs2 0.000877
obs3 0.000186
obs4 0.000648
dtype: float64
WL 237.214209
obs1 0.000588
obs2 0.000587
obs3 0.000285
obs4 0.000494
dtype: float64
mean()では、各カラムの平均値が、std()では各カラムの標準偏差の値が算出されていることが確認できます。そのほか以下のメソッドがあります。
median()
max()
min()
product()
など。
グラフへのプロット¶
上で作成したデータフレームをグラフにプロットしましょう。DataFrameクラスにあるplot()メソッドでプロットしてみます。
引数xにx軸としたいカラムの名前を指定します。
[10]:
spec.plot(x='WL')
[10]:
<AxesSubplot:xlabel='WL'>
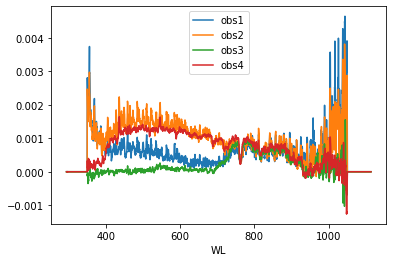
DataFrameのplot()メソッドで描画される図はmatplotlibと組み合わせて使うこともできます。これにより、ほかの種類とのグラフの重ね合わせや、軸やグラフエリアの詳細なカスタマイズができるようになります。
グラフに可視光と近赤外線の範囲を重ね合わせて表示してみましょう。
今回はLandsat 8に積まれているセンサーと同じ波長でRGBと近赤外線(NIR)の波長域を設定してみます。
バンド名 |
名前 |
波長帯(nm) |
|---|---|---|
Band 4 |
青 |
450~510 |
Band 4 |
緑 |
530~590 |
Band 4 |
赤 |
640~670 |
Band 5 |
近赤外 |
850~880 |
[11]:
# matplotlibのインポート
import matplotlib.pyplot as plt
import pathlib
# 波長域の定義
wave_length = {'Blue': {'range':(450, 510), 'color':'Blue'},
'Green': {'range':(530, 590), 'color':'Green'},
'Red': {'range':(640, 670), 'color':'Red'},
'NIR': {'range':(850, 880), 'color':'Gray'}}
# plot範囲の定義
plot_xlim = (wave_length['Blue']['range'][0],
wave_length['NIR']['range'][1])
plot_ylim = (0, 0.002)
# プロットオブジェクトの初期化
fig, ax = plt.subplots()
# 各バンドの範囲をプロット
for band in wave_length:
ax.axvspan(*wave_length[band]['range'],
color=wave_length[band]['color'],
alpha=0.5)
# グラフをプロット
# spec.plot(x='WL', ax=ax, xlim=plot_xlim, ylim=plot_ylim)
spec.plot(x='WL', ax=ax)
# プロットの範囲を変更
ax.set_xlim(plot_xlim)
ax.set_ylim(plot_ylim)
# グラフのタイトル等をプロット
ax.set_xlabel(r'Wave Length (nm)')
ax.set_ylabel(r'Spectral Irradiance ($W m^{-2} nm^{-1}$)')
plt.tight_layout()
# 'out'フォルダの作成
p = pathlib.Path('out')
p.mkdir(exist_ok=True)
# 'out'フォルダに画像として保存
plt.savefig('out/spectral.png')
# 画面へ表示
plt.show()
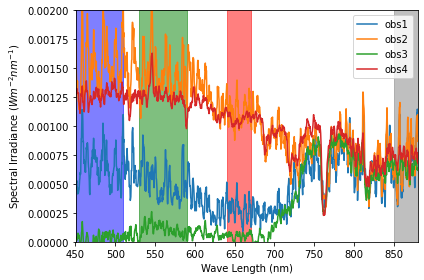
NDVIの計算¶
NDVIは植生の状態をよく反映する指標で、以下の式で定義されます。
マルチスペクトルメータの場合、近赤外の反射率に相当するものは、上記の図の灰色の範囲の平均値、同様に赤色の反射率は赤色の範囲の平均値となります。今回のようなノイズが多いデータの場合、平均値より中央値を用いる方が良いでしょう。
ここからNDVIを算出するため、以下の手順を行います。
赤・近赤外周波数領域における中央値の計算
NDVIの計算
バンドごとの中央値の計算¶
作成したデータフレームから、特定の周波数の範囲における各バンドの値の中央値は、以下の手順で求めることができる。
WLが、赤色の範囲である行のみをデータフレームから抜き出す。
抜き出してできる新たなデータフレームの列ごとの中央値を求める。
上記1,2をNIRについても行う。
行の抽出¶
データフレームから行番号を指定して特定の行を抜き出すには、df[0:5]のような形で行の範囲を指定します。
[12]:
spec_part = spec[300:304]
spec_part
[12]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| 300 | 396.24 | 0.000823 | 0.000999 | 0.000047 | 0.000385 |
| 301 | 396.58 | 0.000787 | 0.000943 | 0.000008 | 0.000388 |
| 302 | 396.92 | 0.000715 | 0.000854 | -0.000011 | 0.000372 |
| 303 | 397.26 | 0.000653 | 0.000783 | -0.000014 | 0.000356 |
赤色の周波数域のデータを抽出するには、「WLの値が[640, 670]の間にある行」を抽出する必要があります。エクセルでファイルを開いて対象の行を探してもいいですが、せっかくなので条件から自動で行を抽出しましょう。
データフレームの抽出では[0:4]の代わりに、[True, False, False, ...]のようなブール値の入ったリストを与えると、データフレームからTrueの行を抽出することができます。([]が入れ子になっていることに注意。)
[13]:
spec_part[[True, False, True, False]]
[13]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| 300 | 396.24 | 0.000823 | 0.000999 | 0.000047 | 0.000385 |
| 302 | 396.92 | 0.000715 | 0.000854 | -0.000011 | 0.000372 |
また、以下のようにカラムを抽出し条件式に当てはめると、条件を満たす場合True、満たさない場合Falseが入ったSeriesを作成することができ、このSeriesも行の抽出に使うことができます。
[14]:
# データフレームからのカラムの抽出
spec['WL']
[14]:
0 294.00
1 294.34
2 294.68
3 295.02
4 295.37
...
2495 1112.93
2496 1113.24
2497 1113.55
2498 1113.86
2499 1114.17
Name: WL, Length: 2500, dtype: float64
[15]:
# Bool値の入ったSeriesの作成
spec['WL'] > 640
[15]:
0 False
1 False
2 False
3 False
4 False
...
2495 True
2496 True
2497 True
2498 True
2499 True
Name: WL, Length: 2500, dtype: bool
このBool値が入ったSeriesは、&や|で結合することで、複数の条件を満たす新たなBool値のSeriesを作成することができます。
[16]:
lines_red = (spec['WL'] > 640) & (spec['WL'] < 670)
lines_red
[16]:
0 False
1 False
2 False
3 False
4 False
...
2495 False
2496 False
2497 False
2498 False
2499 False
Name: WL, Length: 2500, dtype: bool
以上を組み合わせて、赤色の波長範囲の分光放射照度のみのデータフレームは以下のように作成できます。
[17]:
# Seriesでデータフレームを抽出する
spec_red = spec[lines_red]
spec_red
[17]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| 1026 | 640.10 | 0.000515 | 0.001366 | 0.000079 | 0.001136 |
| 1027 | 640.43 | 0.000477 | 0.001336 | 0.000061 | 0.001128 |
| 1028 | 640.77 | 0.000384 | 0.001217 | 0.000038 | 0.001123 |
| 1029 | 641.10 | 0.000328 | 0.001166 | 0.000051 | 0.001110 |
| 1030 | 641.43 | 0.000342 | 0.001139 | 0.000059 | 0.001093 |
| ... | ... | ... | ... | ... | ... |
| 1112 | 668.60 | 0.000357 | 0.001238 | 0.000069 | 0.001107 |
| 1113 | 668.94 | 0.000361 | 0.001303 | 0.000105 | 0.001090 |
| 1114 | 669.27 | 0.000306 | 0.001202 | 0.000082 | 0.001090 |
| 1115 | 669.60 | 0.000298 | 0.001154 | 0.000094 | 0.001066 |
| 1116 | 669.93 | 0.000322 | 0.001117 | 0.000067 | 0.001039 |
91 rows × 5 columns
NIRについても同様にデータフレームを作成できます。
[18]:
lines_nir = (spec['WL'] > 850) & (spec['WL'] < 880)
spec_nir = spec[lines_nir]
spec_nir
[18]:
| WL | obs1 | obs2 | obs3 | obs4 | |
|---|---|---|---|---|---|
| 1667 | 850.28 | 0.000484 | 0.000575 | 0.000674 | 0.000728 |
| 1668 | 850.60 | 0.000505 | 0.000573 | 0.000680 | 0.000750 |
| 1669 | 850.93 | 0.000613 | 0.000674 | 0.000698 | 0.000735 |
| 1670 | 851.25 | 0.000616 | 0.000693 | 0.000708 | 0.000741 |
| 1671 | 851.57 | 0.000542 | 0.000632 | 0.000740 | 0.000713 |
| ... | ... | ... | ... | ... | ... |
| 1755 | 878.70 | 0.001017 | 0.001043 | 0.000736 | 0.000776 |
| 1756 | 879.02 | 0.001117 | 0.001085 | 0.000671 | 0.000732 |
| 1757 | 879.34 | 0.001058 | 0.000997 | 0.000623 | 0.000771 |
| 1758 | 879.67 | 0.001146 | 0.001066 | 0.000637 | 0.000693 |
| 1759 | 879.99 | 0.001115 | 0.001099 | 0.000632 | 0.000701 |
93 rows × 5 columns
中央値の計算¶
基本統計量の確認の際に示したmean()と同様に、DataFrameが持つmedian()メソッドにより各カラムの中央値が計算できます。
[19]:
red_median = spec_red.median()
red_median
[19]:
WL 655.030000
obs1 0.000289
obs2 0.001139
obs3 0.000057
obs4 0.001069
dtype: float64
[20]:
nir_median = spec_nir.median()
nir_median
[20]:
WL 865.150000
obs1 0.000686
obs2 0.000739
obs3 0.000652
obs4 0.000738
dtype: float64
NDVIの計算¶
作成したSeriesからNDVIの計算に不要なWaveLengthの値を抜いておきます。
[21]:
red_median = red_median.drop('WL')
nir_median = nir_median.drop('WL')
Seriesは要素数が同じ場合、四則演算は各要素ごとに行われます。これを分配法則といいます。このため、各obsにおけるNDVIは定義式のようにSeriesを計算することにより求めることができます。
[22]:
NDVI = (nir_median - red_median)/(nir_median + red_median)
NDVI
[22]:
obs1 0.407179
obs2 -0.212833
obs3 0.839210
obs4 -0.182955
dtype: float64
以上でNDVIの算出ができました。